
AI systems today can generate, automate, and assist with impressive accuracy. But their failures, however infrequent, can be costly and unpredictable.
In controlled environments, these systems perform well. But once deployed at scale, they encounter messy inputs, unexpected user behavior, and scenarios they were never designed for. This is where things begin to break.
At CloudFest 2026, this gap was framed as “the missing 5%.”
Mirco Pyrtek, Director of Applied AI and Data Innovation at WebPros, addressed this gap in his session titled ‘The Missing 5%: LLMOps, Guardrails & Observability for Agentic AI at Scale.’
In this blog, we explore why this gap exists, the real risks it creates at scale, and the practical framework, including LLMOps, guardrails, and observability, needed to close it.
Watch the Full Session
Watch the full session here:
The Gap Between AI Adoption and AI Reliability
AI adoption is accelerating at a pace few technologies have matched.
What was experimental just a year ago is quickly becoming embedded into real products and workflows. Agentic AI is moving from niche use cases to mainstream enterprise adoption, with projections showing a sharp rise in deployment across applications.
On the surface, this signals maturity. But in practice, it exposes a different problem.
Most AI systems perform well in controlled settings. They handle expected inputs, follow structured prompts, and deliver outputs that appear reliable. This is where many pilots succeed, and where most evaluations stop.
Real-world usage is very different.
AI systems do not behave like traditional software. The same input can produce different outputs, and behavior can shift based on context, phrasing, or user intent.
As these systems scale, this variability becomes more visible. Users behave unpredictably. Inputs are messy, incomplete, or intentionally adversarial. And with more interactions, the likelihood of failures to adhere to instructions increases. This is where the “missing 5%” becomes visible.
What makes this gap critical is not how often failures occur, but what happens when they do.
In the session, this was illustrated through real-world examples:
- AI agents being manipulated into making incorrect or binding commitments
- Customer-facing systems generating inaccurate information that led to legal consequences
- AI tools being misused to create harmful or deceptive content at scale
These are not isolated incidents. They reflect a broader pattern.
The number of reported AI-related incidents has been steadily increasing, reinforcing that this is a systemic challenge rather than a series of one-off failures.
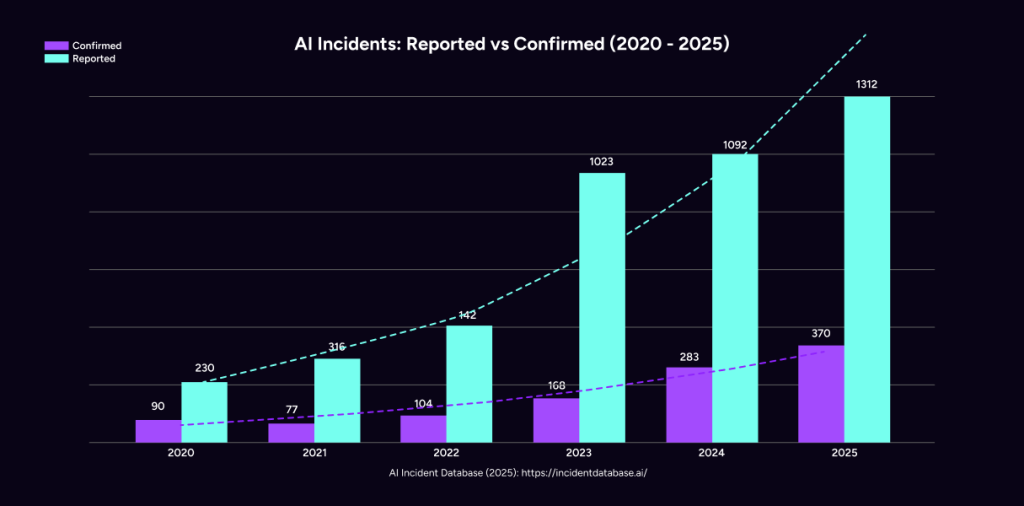
The implication is clear:
The challenge is no longer building AI that works.
It is building AI systems that can handle variability, manage failures, and behave reliably under real-world conditions. This is where most AI initiatives begin to stall.
Why Traditional Approaches Fall Short
And this is where conventional thinking breaks down. At this point, it is tempting to assume that improving model quality will solve the problem.
Better models, more data, stronger prompts.
But this approach alone is not enough. The issue is the complexity of real-world environments, far beyond the conditions these systems were trained or tested in.
Traditional software engineering relies on predictability. Inputs are defined. Logic is deterministic. Outputs are consistent.
AI systems operate differently.
They are probabilistic. They generate responses based on patterns, not fixed rules. And they are highly sensitive to context, phrasing, and user behavior.
This introduces a new operational challenge.
Failures are no longer limited to bugs in code. They emerge from ambiguous inputs, misaligned context, gaps between outputs and real-world policies, and interactions that push systems beyond their intended scope.
What makes this more complex is that many of these issues cannot be fully anticipated during development.
As discussed in the session, AI systems effectively have an “unbounded attack surface.” Once deployed, they are exposed to scenarios that teams did not explicitly design for. This is where most pilots begin to break down.
They are built to demonstrate capability, not to handle variability. And when variability increases, through scale, user diversity, or new use cases, the system begins to show cracks.
This is also why simply adding more context or instructions does not solve the problem. In fact, it often makes it worse, introducing additional complexity without addressing the underlying issue.
What is needed instead is a shift in mindset.
From building AI features to operating AI systems. From focusing on outputs to managing behavior. And from treating failures as exceptions to designing systems that expect them.
This is where LLMOps come in.
Introducing LLMOps: From AI Features to AI Systems
LLMOps is not a single tool or layer. It is an operational framework designed to manage AI systems in production, where variability, risk, and scale are constant.
LLMOps is the discipline that makes AI systems production-ready. At its core, LLMOps answers a simple but critical question:
How do you ensure an AI system behaves as expected, even when conditions are unpredictable?
To address this, we approach AI not as isolated features, but as interconnected systems with clearly defined requirements. Instead of starting with models or tooling, the focus begins with the application itself.
What risks does it carry? What kind of input will it receive? What outcomes must be controlled or prevented?
This requirement-driven approach ensures that safeguards are not added as an afterthought but built into the system from the start.
This is illustrated through the lens of WebPros’ AI products:
- Nova: Our AI application builder where outputs must remain compliant and safe
- XOVI AI: Our Generative Engine Optimization (GEO) tool where accuracy and relevance must be tightly controlled for content improvement suggestions
- Plesk, cPanel, and WHMCS: AI assistants where sensitive user data must be detected and protected
Each of these systems operates in a different context. Each carries different risks. But they all rely on the same underlying principle: AI systems must be designed with operational control in mind.
This is what LLMOps enable.
And to make it actionable, the framework is built on three interconnected pillars, each addressing a different aspect of reliability at scale.
The Three Pillars of LLMOps
To make AI systems reliable at scale, LLMOps is structured around three core pillars. Each plays a distinct role, but their real strength comes from how they work together.
Observability: Understanding What Your AI Is Doing
AI systems are often treated as black boxes. You provide an input, receive an output, and evaluate whether it looks correct.
But at scale, this is not enough.
Observability brings visibility into how the system behaves across real interactions. It allows teams to move beyond surface-level outputs and understand patterns over time.
This includes:
- Tracking how users interact with the system
- Identifying where conversations break down
- Measuring latency, cost, and usage
- Capturing edge cases and unexpected behavior
One of the most important outcomes of observability is the ability to uncover what was not anticipated. These “unknown unknowns” are where most risks originate, and where observability directly informs the protection layer by translating them into guardrails.
Instead of reacting to failures after they occur, observability helps teams detect early signals and continuously improve system performance.
Guardrails: Controlling AI Behavior
If observability helps you understand what is happening, guardrails help you control it. Guardrails act as safety layers around the model, ensuring that both inputs and outputs stay within acceptable boundaries.
They operate in two directions:
Inbound guardrails focus on what goes into the system. This includes detecting prompt injection attempts, filtering harmful inputs, and identifying sensitive data such as personal or financial information.
Outbound guardrails focus on what comes out of the system. This includes checking for hallucinations, enforcing compliance with policies, and ensuring responses align with real data and intent.
In practice, no single method is sufficient. Guardrails are typically implemented using a combination of:
- Rule-based checks for known patterns
- Machine learning classifiers for flexible detection
- Secondary models that evaluate outputs for quality and safety
This layered approach ensures that systems are both efficient and adaptable, balancing precision with flexibility. All these approaches, however, rely on underlying infrastructure to power their models and algorithms, bringing us to the third pillar.
Infrastructure: Powering AI Sustainably
The final pillar is often overlooked, but it becomes critical as systems scale.
AI is compute-intensive. Every interaction consumes resources, and as usage grows, so do costs and performance requirements. Organizations typically choose between three approaches:
- Consumption-based APIs, which are easy to start with but can become expensive at scale
- Owning infrastructure, which offers control but requires significant upfront investment
- Leasing infrastructure, which provides a balance between cost predictability and flexibility
The right choice depends on scale, usage patterns, and long-term strategy.
What the session made clear is that infrastructure decisions cannot be an afterthought. They directly impact both the economics and reliability of AI systems.
Individually, each pillar addresses a specific challenge. But the real value of LLMOps lies in how they connect.
Observability identifies issues. Guardrails enforce control. Infrastructure enables both to operate efficiently at scale. Together, they form a continuous loop that allows AI systems to evolve, adapt, and remain reliable over time.
The Continuous Loop That Makes AI Reliable
One of the most important ideas from the session was that LLMOps is not a one-time setup. It is an ongoing cycle.
AI systems are not static. They evolve with new models, changing user behavior, and expanding use cases. What works today may not hold tomorrow. This is why reliability cannot be treated as a fixed state. It has to be continuously maintained.
The framework follows a simple but powerful loop: Monitor → Guard → Optimize → Repeat
It begins with observability.
As systems interact with real users, observability captures how they behave in practice. It surfaces failure points, unexpected inputs, and patterns that were not visible during development.
These insights then feed directly into guardrails.
New risks become new rules. Edge cases become enforceable checks. Over time, guardrails evolve to cover a wider range of scenarios, reducing the likelihood of repeated failures.
From there, the focus shifts to optimization.
This includes refining prompts, improving system design, testing new models, and evaluating performance against real-world data. It also involves making infrastructure decisions that balance cost, speed, and scalability.
But the loop does not end there.
Every change, whether it is a new model, a new feature, or a new user behavior, introduces new variables. And with those variables come new risks, bringing the system back to monitoring.
This continuous cycle allows AI systems to move from fragile to resilient. It also highlights an important shift in mindset.
AI reliability is not achieved by eliminating all failures. It is achieved by building systems that can detect, adapt, and respond to them over time.
That is what closes the “missing 5%.”
The Economics of the Missing 5%
As AI systems scale, cost becomes impossible to ignore. What works in a pilot, due to low usage, limited guardrails, and minimal oversight, does not translate to production. Every interaction, every validation layer, and every safeguard adds to the total cost of operating AI.
But focusing only on usage costs misses the bigger picture.
The real question is what it costs when AI fails.
Failures in the “missing 5%” can lead to reputational damage, legal exposure, and loss of customer trust. In many cases, these costs far outweigh the investment required to prevent them. For example, the average cost of a single data breach was measured around $4.4M by IBM in 2025. An AI agent with access to sensitive data could cause that with a single failure.
This is what reframes LLMOps as a risk management strategy.
From AI That Works to AI You Can Trust
AI capability is no longer the bottleneck. Reliability is.
What this session made clear is that the gap between pilots and production is operational. Systems that perform well in controlled environments often fail when exposed to real users, real inputs, and real scale.
Closing that gap requires intent.
Start by making AI behavior visible. If you cannot see how your system behaves in the real world, you cannot improve it.
Then put control in place. Guardrails should be designed into the system from the start.
And finally, plan for scale early. Infrastructure and cost decisions will shape how far your AI can go.
The teams that succeed will not be the ones with the most advanced models. They will be the ones that build systems designed to handle uncertainty.
Because the goal is not to eliminate the “missing 5%.”
It is to be prepared for it.
That is what turns AI from something that impresses into something that can be trusted and scaled.